Primeras pruebas de la IA Wargamer

Cuando OpenAI introdujo la posibilidad de crear Custom GPTs, desarrollé Wargame World, un modelo personalizado diseñado para asistir con reglamentos y guías oficiales. Este sistema permite realizar consultas sobre reglamento de Flames Of War, esquemas de colores Vallejo, crear listas de ejércitos y resolver dudas en general sobre Flames of War y otros wargames.
Sin embargo, para la Campaña del Norte de África, necesito una solución más específica, flexible y personalizada. Además, requeriré de capacidades avanzadas, como la integración de visión.
Por ello, he diseñado un nuevo sistema base compuesto por las siguientes herramientas:
Herramientas del sistema IA
- LM Studio: Servidor de IA donde se cargarán los modelos necesarios.
- Anything LLM: Un entorno de chat similar a ChatGPT, que permite cargar documentos, imágenes e interactuar de forma general con la IA, todo en local y de manera totalmente privada, sin transferir datos a servidores externos, ni siquiera a LM Studio.
Esto previsiblemente se ampliará en el futuro con alguna pieza en Arduino para lanzamiento de dados, alguna cámara para la visión de la IA y lo que vaya surgiendo.
Selección de modelos LLM
1. LLaMA 2 y 3 (Meta)
- Razón para usarlo:
- Alta calidad en generación de texto.
- Modelos desde 7B a 70B parámetros, adecuados para diferentes capacidades de hardware.
- Dónde encontrarlo: LLaMA en Hugging Face
- Hardware recomendado:
- 7B: 12 GB VRAM.
- 13B: 24 GB VRAM (o CPU con RAM alta).
- Integración con LM Studio: Compatible y ampliamente soportado.
2. Mistral (Mistral AI)
- Razón para usarlo:
- Rendimiento competitivo con menor consumo de recursos.
- Ideal para hardware limitado.
- Modelo destacado: Mistral 7B.
- Dónde encontrarlo: Mistral en Hugging Face
- Hardware recomendado: 7B requiere alrededor de 10-12 GB de VRAM.
3. Falcon (Technology Innovation Institute)
- Razón para usarlo:
- Excelente para generación de texto coherente y preciso.
- Modelos como Falcon-7B, Falcon-10B y Falcon-40B.
- Dónde encontrarlo: Falcon en Hugging Face
- Hardware recomendado:
- 7B: 16 GB de RAM.
- 40B: Hardware más potente o soluciones distribuidas.
4. GPT-NeoX (EleutherAI)
- Razón para usarlo:
- Open source con modelos grandes y configurables.
- Basado en GPT-3.
- Dónde encontrarlo: GPT-NeoX en GitHub
- Hardware recomendado: Modelos pequeños como GPT-NeoX-20B requieren al menos 40 GB de VRAM.
5. Phi-4 (Microsoft)
- Razón para usarlo:
- Phi-4 es un modelo de lenguaje de 14 mil millones de parámetros que destaca por su capacidad para generar texto coherente y preciso, siendo especialmente útil en contextos históricos y de estrategia militar.
- Dónde encontrarlo: Microsoft en Huggingface
- Hardware recomendado:
- Requiere hardware potente; se recomienda una GPU de alta gama con al menos 24 GB de VRAM.
- Integración con LM Studio:
- Compatible con LM Studio, permitiendo su implementación en entornos locales.
Modelos Ligados al Contexto Histórico o Geográfico
Adecuados para temas relacionados con historia, estrategia militar y wargaming.
1. BELLE (BLOOM Enhanced)
- Razón para usarlo:
- Especializado en tareas multilingües e históricas.
- Dónde encontrarlo: BELLE en Hugging Face
- Hardware recomendado: Compatible con GPUs de gama media.
2. OpenAssistant (LAION)
- Razón para usarlo:
- Diseñado como un asistente general, pero personalizable con datos específicos.
- Dónde encontrarlo: OpenAssistant en Github
- Hardware recomendado: Similar a LLaMA-13B.
3. Flan-T5 (Google)
- Razón para usarlo:
- Ligero y eficiente para tareas específicas.
- Ideal para generar narrativas y explicaciones.
- Dónde encontrarlo: Flan-T5 en Hugging Face
- Hardware recomendado:
- Pequeñas versiones (Base): ~12 GB de RAM.
- XXL: Hardware potente.
Modelos Cuantizados para Hardware Limitado
Si necesitas optimizar para hardware más ligero, considera estas opciones:
1. LLaMA 2 4-bit/8-bit
- Razón para usarlo:
- Cuantización reduce el uso de memoria.
- Dónde encontrarlo: Hugging Face LLaMA Cuantizado
2. GPTQ (Quantized Models)
- Razón para usarlo:
- Implementación eficiente para modelos grandes.
- Dónde encontrarlo: GPTQ en GitHub
Recomendaciones Finales
- Para manejo de reglamentos y consultas rápidas:
- LLaMA 2/3 7B o Mistral 7B.
- Para generación de narrativa o contexto histórico:
- Falcon 7B o Flan-T5 XXL.
- Para hardware limitado:
- LLaMA 2/3 4-bit o Mistral 7B.
Configuración del sistema
No abordaré los pasos de instalación, ya que estos pueden consultarse en las guías oficiales de LM Studio y Anything LLM. Más que recomendable su lectura, para familiarizarse con los conceptos básicos de ambas aplicaciones.
En su lugar, nos centraremos en la selección de modelos y en cómo conectar Anything LLM con LM Studio para aprovechar su funcionalidad al máximo.
Paso a paso
1. Configuración de LM Studio
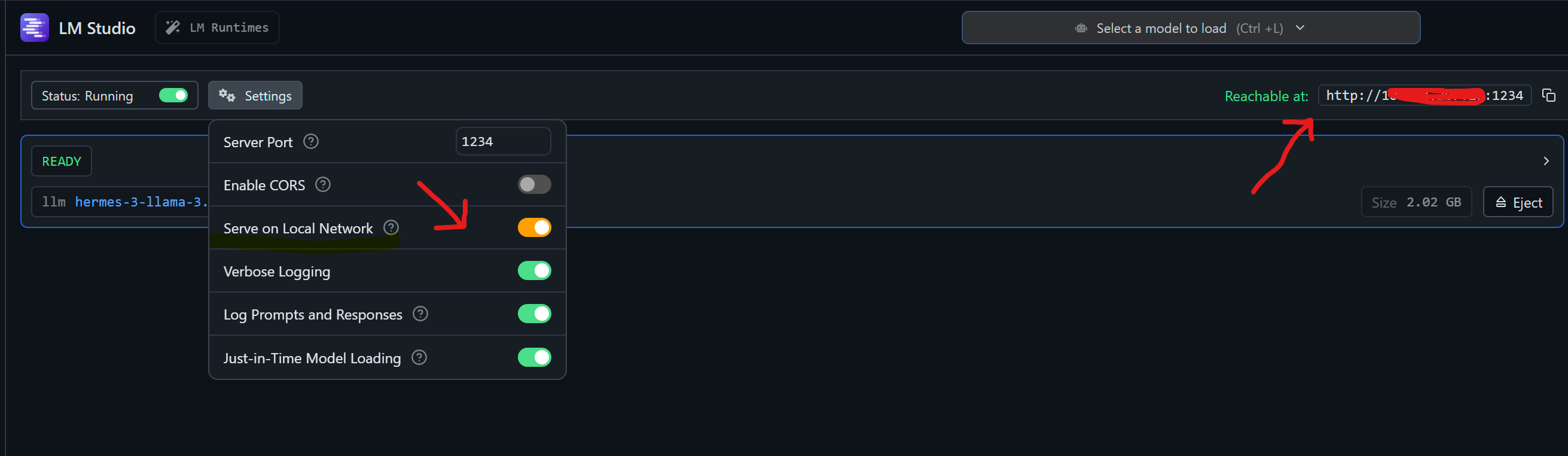
- Descargamos y seleccionamos un modelo, luego activamos la opción ‘Serve On Local Network’ en la configuración de LM Studio.
- Si la opción se activa correctamente, aparecerá el estado ‘Reachable’ junto con la dirección IP de la red LAN donde el servicio está disponible.
- De lo contrario, Anything LLM solo podrá conectarse desde la misma máquina en la que se está ejecutando LM Studio.
2. Configuración de Anything LLM
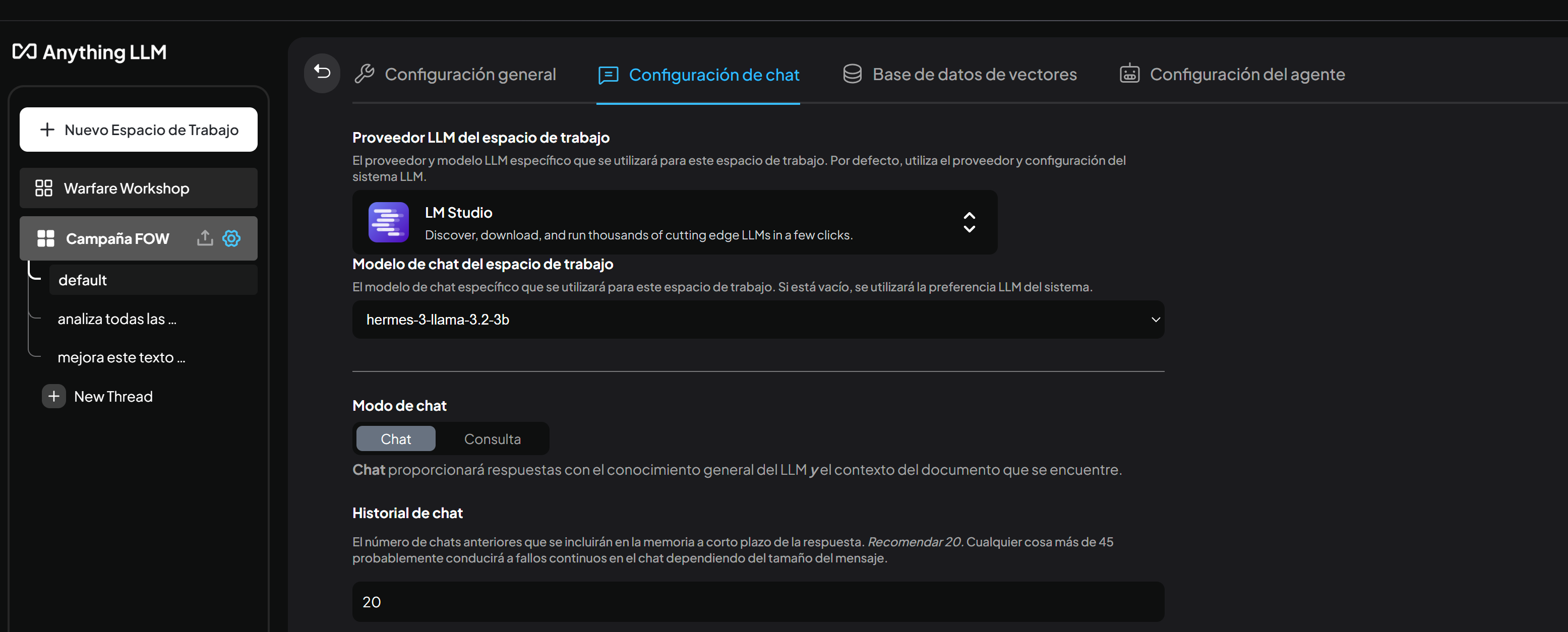
- Creamos un nuevo espacio de trabajo y accedemos a la configuración de chat.
- Seleccionamos LM Studio como proveedor de LLM, elegimos el modelo deseado de la lista desplegable (previamente lo tendremos que haber descargado desde LM Studio).
- Si nos conectamos desde la misma máquina, utilizamos
http://127.0.0.1:1234/v1. - Si nos conectamos desde la red LAN, utilizamos
http://192.168.1.x:1234/v1o la dirección marcada como ‘Reachable’ en la configuración. - Si deseamos añadir una capa adicional de seguridad al sistema, podemos utilizar herramientas como Tailscale, Esto no solo refuerza la protección de las conexiones, sino que también permite conectar equipos desde Internet a nuestro servidor de IA de manera segura y eficiente.
- Actualizamos el espacio de trabajo.
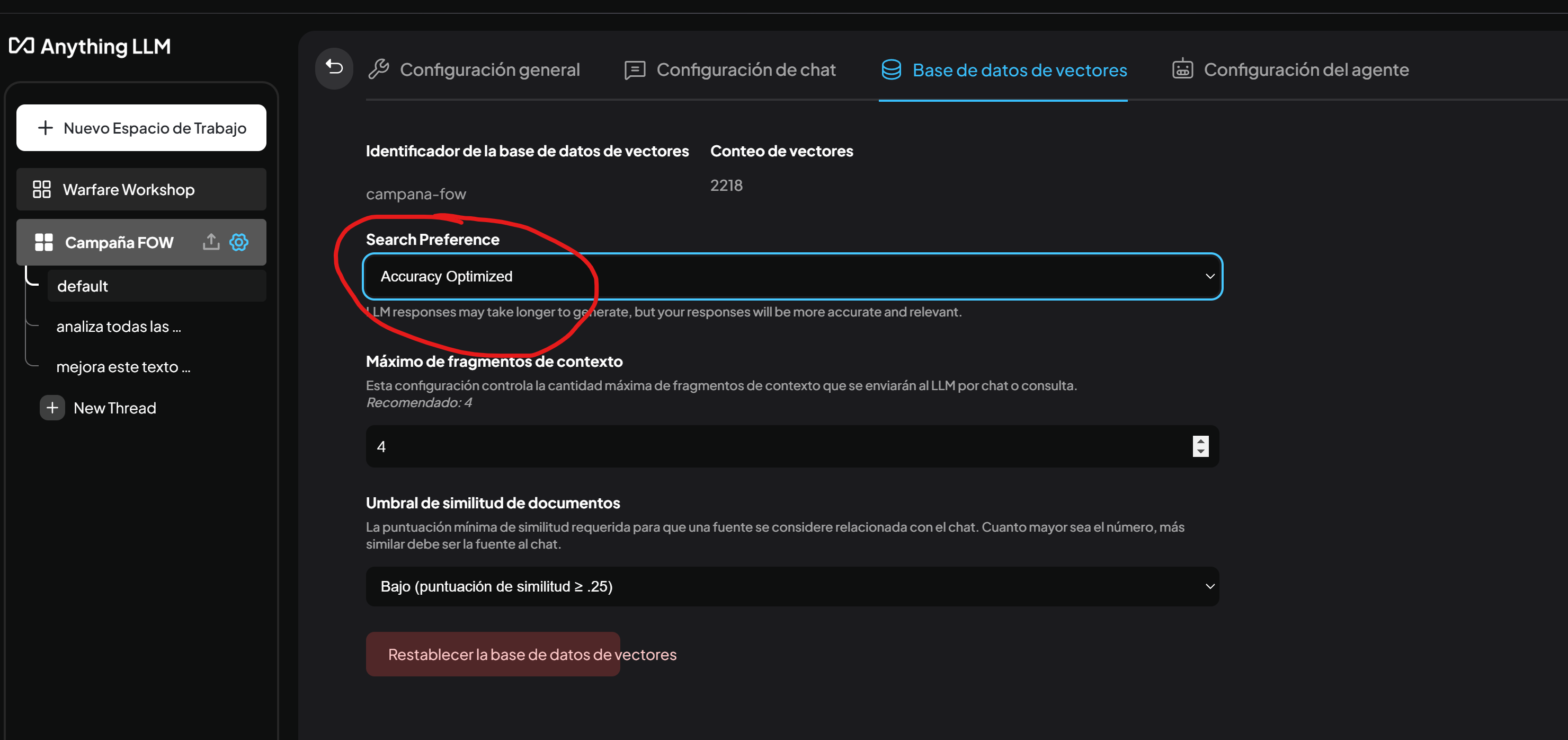
3. Optimización de precisión
- En la base de datos de vectores, activamos la opción ‘Accuracy Optimized’ para mejorar la relevancia y precisión de las respuestas. Sin embargo, es importante tener en cuenta que esto puede incrementar ligeramente el tiempo de generación de resultados.
4. Selección de modelos
- Para las pruebas iniciales, comenzaremos con Phi 4 y las últimas versiones de Llama, adecuados para las limitaciones de hardware (32 GB de RAM y 12 GB de VRAM).
- Añadimos documentos relacionados con la campaña a la memoria contextual desde Anything LLM.
- Con la cantidad de literatura de Flames Of War existente, para diferentes versiones del reglamento, y para evitar confundir a la IA con los distintos sistemas de puntuación y reglas, añadiremos solamente la documentación relevante de la versión 4, referente a la campaña del Norte de África, y los guiones de cada una de las misiones.
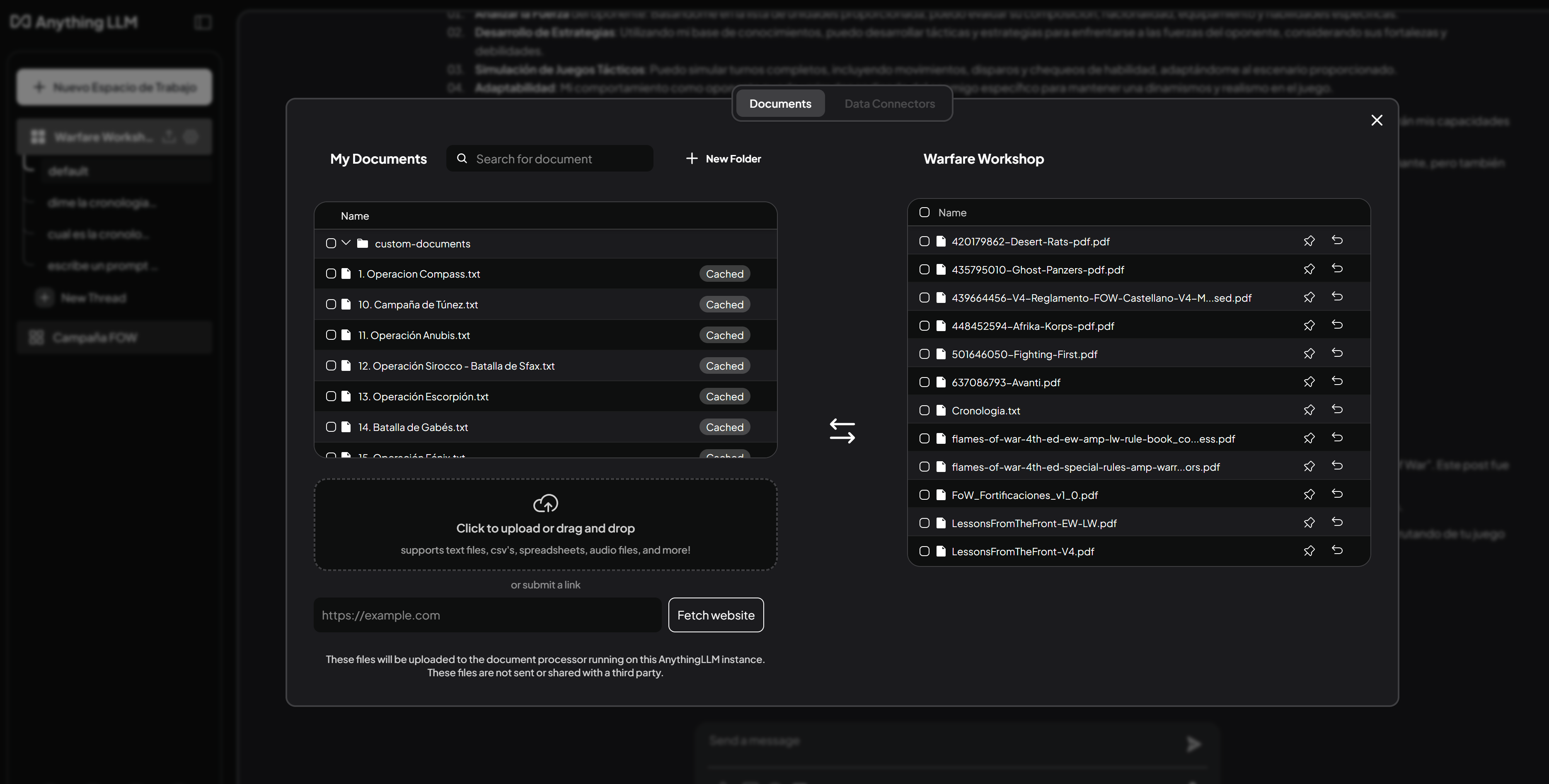
- En la sección Data Connectors, contamos con un web scraper que permite agregar contenido web directamente. En mi caso, incluiré artículos relacionados con las unidades que se utilizarán en las listas de ejércitos, además de varios artículos de la sección de wargames. También es posible elegir otras fuentes, pero es importante tener cuidado de no incumplir las políticas de uso de esos sitios web, especialmente si se incrementa el nivel de recursividad del scraping (depth), ya que podría sobrecargar tanto el sistema como los servidores del sitio objetivo.
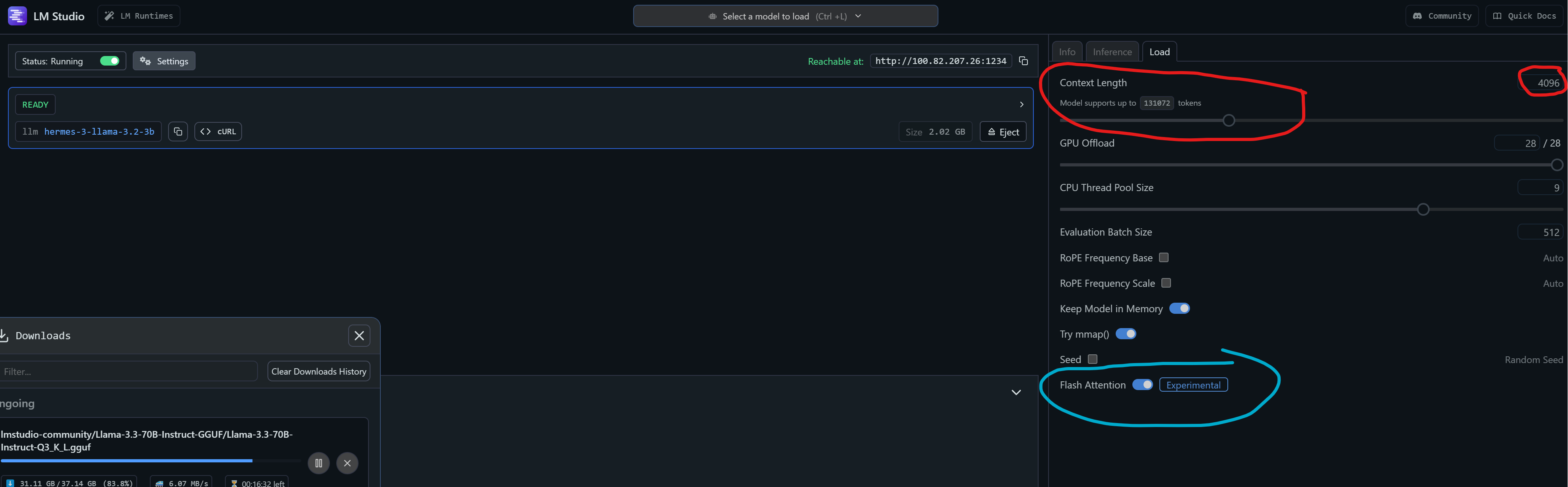
5. Ajustes adicionales en LM Studio
- Configuramos parámetros como la amplitud del contexto, comenzando con 4096 tokens y probando hasta unos 8000, un rango manejable para el hardware disponible (una RTX 3080ti). Ya que estamos en modo testing, activaremos también ‘Flash Attention’, lo que debería mejorar la eficiencia, al menos en los modelos que lo soporten.
Una vez realizados estos ajustes, contamos con un sistema de inteligencia artificial completamente funcional. Este sistema permite realizar consultas sobre la documentación previamente integrada, con la flexibilidad de ampliar su base de conocimiento incorporando nueva información según nuestras necesidades. Resulta especialmente interesante añadir documentación histórica o específica sobre determinadas batallas o escenarios para enriquecer aún más su utilidad.
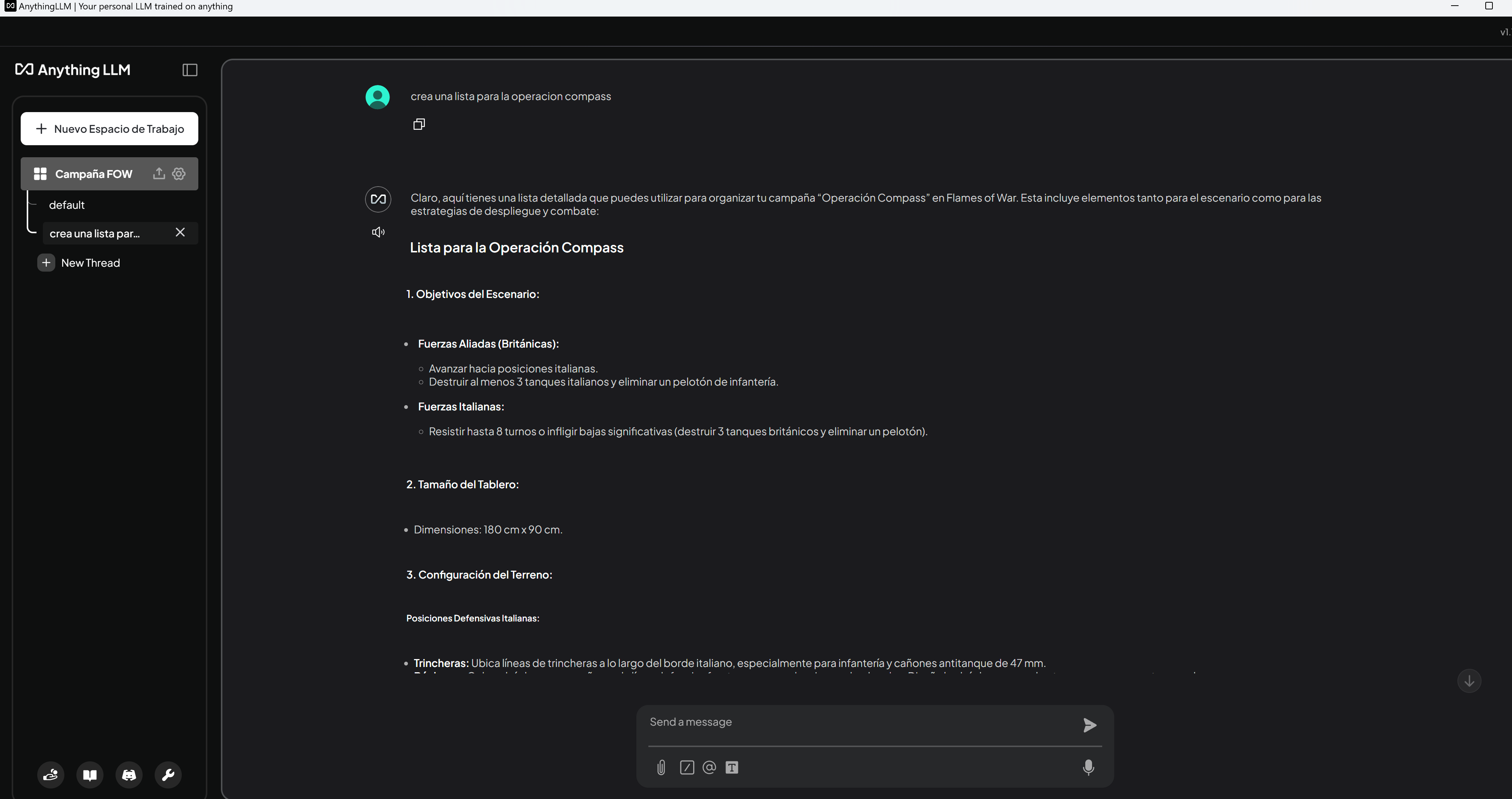
Como podemos observar, los resultados aún son bastante mejorables, aunque ya muestran un cierto nivel de coherencia. Es necesario ajustar el formato para que realmente se asemeje a una lista de Flames of War, y mejorar la calidad de las respuestas. Esto lo lograremos mediante la configuración de los prompts del sistema y otros ajustes que exploraremos más adelante.
Este sistema no solo ofrece una mayor flexibilidad y privacidad, sino que también permite conectar múltiples clientes de Anything LLM a un único servidor de IA en la red interna. Esto resulta ideal para entornos donde se requiera gestionar varios chats (como desde un portátil, un teléfono, etc.) y agentes de IA simultáneamente. ¡Muy pronto veremos cómo este enfoque se aplica en la campaña del Norte de África y los resultados obtenidos en las pruebas!







Publicar comentario